
什么是大小端
大端小端只是在内存(或网络)中的字节顺序不同,比如16进制数字0x12345678,这个在一般系统中都是四字节int类型,在大端字节序中表示为:
| 0x12 | 0x34 | 0x56 | 0x78 |
在小端字节序中表示为:
| 0x78 | 0x56 | 0x34 | 0x12 |
很明显可以观察到,大端的字节顺序和数字的顺序相同,而小端字节序完全相反。
所以大端序指的是:数字的高位存储在低地址,低位存储在高地址, 小端序指的是:数字的高位存储在高地址,低位存储在低地址。简单来说大端序就是人类读写数值的方式,小端序更像是机器读写数值的方式。
- 高位和低位:通常人类书写数字的时候,都是从数字的左边往右边书写,数字的左边就是高位,数字的右边就是低位。如果可以选择往银行卡余额的最高位或者最低位加一,高位加一和低位加一的结果差别是显而易见的。
-
高地址和低地址:编程中的内存地址都是逻辑地址,所以一个
C Style风格的数组,不论是分配在栈上还是在堆上,其内存地址一定是递增的。 - 内存中的的字节顺序是大端还是小端主要跟CPU相关,最常见的X86处理器都是小端序模式。
下面这段C语言代码可以更清楚的说明大小端:
#include <stdio.h>
int main(){
int i = 0x12345678;
char*c = (char*)&i;
for(int n=0;n<sizeof(int);++n){
printf("address=0x%x value=0x%x\n", &c[n], c[n]);
}
return 0;
}
代码将一个数值为16进制的0x12345678强制转换为char数组,并依次取出char数组的四个元素并打印出其地址和数值,其实此时char数组的四个元素就分别对应int的四个字节,打印地址和值就能知道字节位对应的地址是多少了。此段代码在我的电脑中运行的结果为:
address=0xec60c148 value=0x78
address=0xec60c149 value=0x56
address=0xec60c14a value=0x34
address=0xec60c14b value=0x12
地址是递增的,可以看到int数值的低字节位0x87位于地址的低位0xec60c148,高字节位0x12位于地址的高位0xec60c14b,按照小端序的定义,所以我的CPU是小端序。
为什么有大小端的区分
为什么要区分大小端呢,统一大端或者统一小端不是省去了很多的麻烦吗?
- 大端:人类习惯读写大端字节序,生活中看到的数值全部都是大端字节序;如果CPU是大端字节序,判断数值正负和比较大小会方便很多。
- 小端:计算机电路如果先处理低位字节,效率相对比较高,在做数值运算时只要依次取字节即可。再比如C语言的强制类型转换,将一个
int转换成short,小端序只需要将int型的前两位复制给short就可以了。桌面处理器基本都是小端序。
如何运行时确定CPU大小端
当自己的代码需要运行在不同系统上,而且处理的数据跟字节序相关时,如何在运行时确定运行的CPU是大端还是小端呢?上面的C语言代码示例能够很清楚的说明大小端的区别,稍微修改一下就可以判断是否是小端了:
#include <stdio.h>
bool is_littlendian(){
int i = 1;
return ((*(char*)&i)==1);
}
int main(){
printf("my Cpu is %s\n", is_littlendian()?"little-endian":"big-endian");
return 0;
}
或者不使用强制转换,利用union的特性来判断:
#include <stdio.h>
bool is_littlendian(){
union {
char c;
int i;
} check;
check.i = 1;
return check.c==1;
}
int main(){
printf("my Cpu is %s\n", is_littlendian()?"little-endian":"big-endian");
return 0;
}
网络字节序
其实大小端各有优缺点,各个硬件产商可能基于不同的取舍,分别选择了大端或者小端,但是在网络传输中的字节序都是大端序。
主要原因是连入互联网的设备非常非常多,而且设备之间的差异很大,若一个设备想跟网络中的任意设备通信,就必须实现相同的通信协议栈,就得选择一个字节序。但这也不能解释为什么选择大端而不是小端,可能是历史原因吧。
我们可以利用Wireshark 抓包工具来验证网络传输用的是大端字节序。
打开Wireshark开启抓取任意一个连接到网络中的网卡,很快就会出现大量的网络数据包,任意选择一个TCP数据包打开包内容,比如我抓到的一个包:
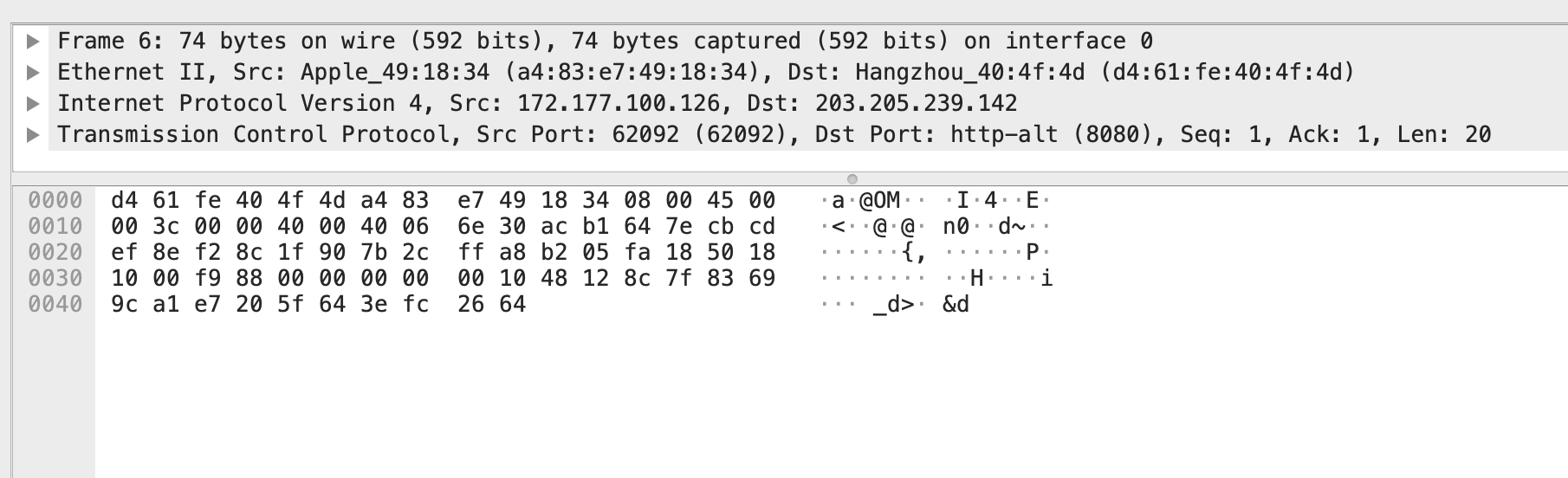
展开Internet Protocol Version 4并选择Source:
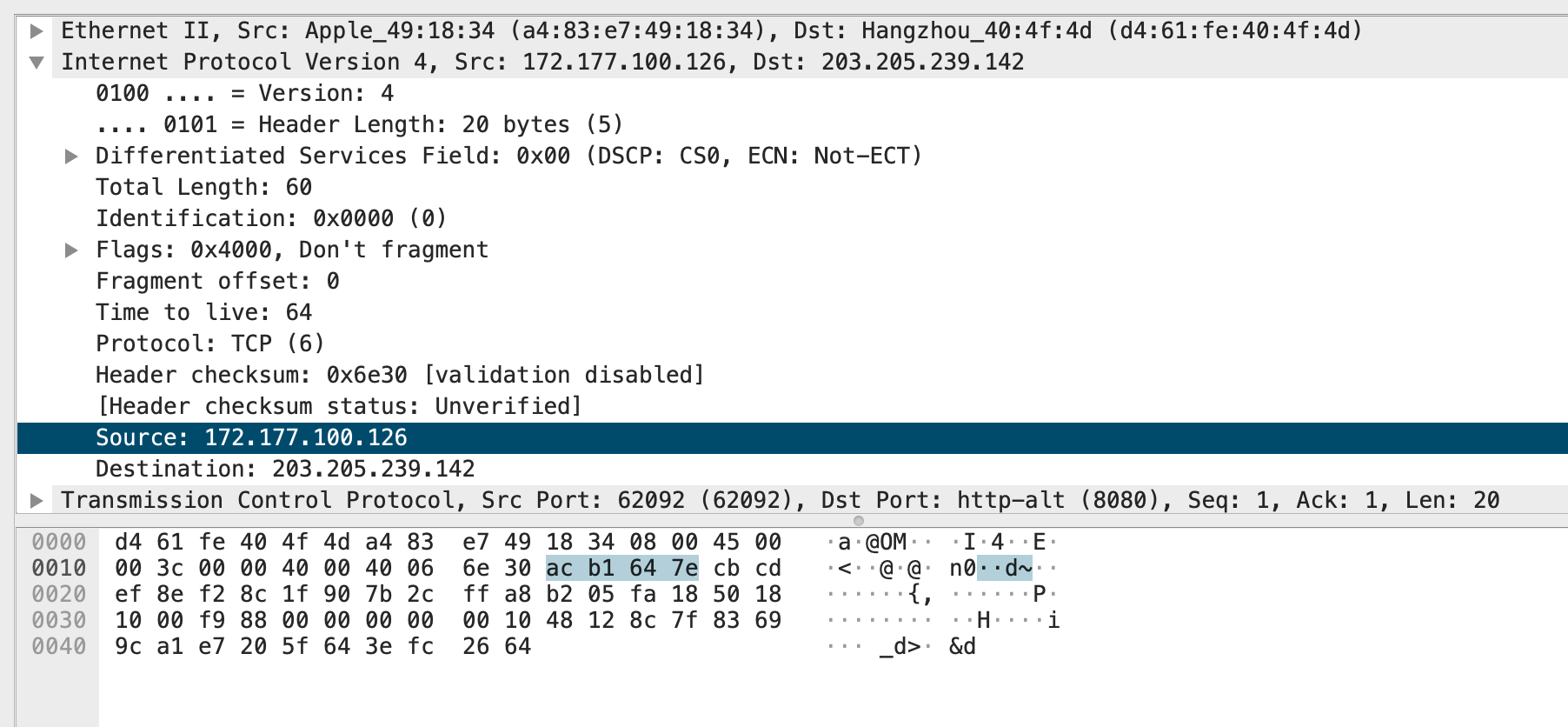
Wireshark会自动把对应数据包的16进制部分高亮,可以看到,地址172.177.100.126高亮部分是ac b1 64 7e,简单计算一下ac对应的二进制是1010 1100,转换成10进制是27+06+25+04+23+22+01+01=172。那么ac b1 64 7e就是地址172.177.100.126在网络中传输的实际字节。172.177.100.126是点分十进制,简单来说这就是一个整型的数值,所以使用大端序和小端序表示肯定是不一样的。
如果没有规定网络字节是大端序呢?我们知道,ac b1 64 7e是地址172.177.100.126的大端序表示,当按字节传输到一个小端序的机器上,就解析成小端序整型7e 64 b1 ac,对应的地址也就变成了126.100.177.172,这显然不是我们想要的。
地址在linux下使用函数inet_addr转换,函数的返回值作为地址信息在网络上传输。
另外网络协议栈中的长度、端口号、checksum等字段都需要用网络的大端序。
常见大小端转换
一般来说,接触底层的通讯协议或者做协议开发的会需要注意端序的问题,应用开发中用到的协议大部分都是工作在传输协议之上的应用层协议,比较典型的http、snmp、protobuf等,这些协议在处理整型数据的时候也是经过了端序的处理。比如protobuf协议在传输整型数据的时候使用的varint编码,使用的就是小端序进行网络传输,所以我们在使用协议传输整型数值的时候不需要关心对方端序的问题。
但是如果需要编写字节序相关的程序时该怎么做呢,系统一般提供了字节序转换的函数:
- htons()
- htonl()
- ntohs()
- ntohl()
上面的h指的是host,n指的是net,s指的是short,l指的是long,比如htonl指的是本地到网络的32位的字节序转换。
我的电脑是mac系统Intel的CPU,我的htonl的实现是:
#define htonl(x) \
((__uint32_t)((((__uint32_t)(x) & 0xff000000) >> 24) | \
(((__uint32_t)(x) & 0x00ff0000) >> 8) | \
(((__uint32_t)(x) & 0x0000ff00) << 8) | \
(((__uint32_t)(x) & 0x000000ff) << 24)))
可以看到,是把高字节和低字节进行移位交换来实现的。
依赖这四个函数就可以编写出字节序无关的程序了,如果系统就是大端序的,这四个宏就会是空实现,不会对字节序作任何改动。
上文中提到的inet_addr函数就是依赖htonl来做了大端序转换。但是系统中没有找到实现的代码,下面是Nginx 源码中的实现:
in_addr_t
ngx_inet_addr(u_char *text, size_t len)
{
u_char *p, c;
in_addr_t addr;
ngx_uint_t octet, n;
addr = 0;
octet = 0;
n = 0;
for (p = text; p < text + len; p++) {
c = *p;
if (c >= '0' && c <= '9') {
octet = octet * 10 + (c - '0');
if (octet > 255) {
return INADDR_NONE;
}
continue;
}
if (c == '.') {
addr = (addr << 8) + octet;
octet = 0;
n++;
continue;
}
return INADDR_NONE;
}
if (n == 3) {
addr = (addr << 8) + octet;
return htonl(addr);
}
return INADDR_NONE;
}
调用结果和系统的一致。可以看到,函数的最后调用了htonl来做端序转换。
左移与右移
虽然存在大端序和小端序的区别,但是左移和右移不需要关心端序的差别,原因是左移和右移的位操作是逻辑操作,可以通过如下代码验证:
#include <stdio.h>
int main(){
int i = 2;
int j = i >> 1;
printf("i = %d, j = %d\n", i, j);
return 0;
}
i的值是2,二进制是0010,我的电脑是小端序,2在内存中是0100,右移后一位后,j的值应该是0010,也就是3才对,运行后得到的结果是:
i = 2, j = 1
可以证明左移和右移不是真实的内存逻辑地址移位,而是逻辑操作。